Sí, ChatGPT ahora puede decirte dónde fue tomada una foto… ¡y con una precisión inquietante! Si creías haber visto todas las innovaciones posibles en IA, espera a descubrir lo que OpenAI ha desarrollado con sus nuevos modelos o3 y o4-mini.
Este avance no solo muestra una mejora técnica: redefine lo que entendemos por “comprensión visual” en los modelos de lenguaje. En este artículo te voy a desgranar en profundidad qué significa esto, por qué es tan revolucionario en educación y qué implicaciones éticas, pedagógicas y epistemológicas abre para el futuro inmediato.
💥 “Esto cambia las reglas del juego.” Los sistemas ya no solo responden: razonan visual y geoespacialmente.
🔍 Contexto: ¿qué han presentado OpenAI y por qué es tan importante?
🧩 Los modelos o3 y o4-mini traen el “pensamiento visual” al escenario
OpenAI ha introducido recientemente dos nuevos modelos de razonamiento para ChatGPT, llamados o3 y o4-mini. Aunque la atención pública suele centrarse en la generación de texto, estos modelos han dado el salto más potente en otra dirección: la capacidad de “pensar con imágenes”.
¿Qué significa esto en términos técnicos? Significa que el sistema no solo ve una imagen como un conjunto de píxeles, sino que genera razonamiento explicativo basado en los elementos visuales presentes, y los integra como parte de su proceso de toma de decisiones o inferencias.
🧠 “Pensar con imágenes” implica ir más allá de identificar objetos: supone contextualizar, deducir, relacionar y argumentar a partir de la información visual.
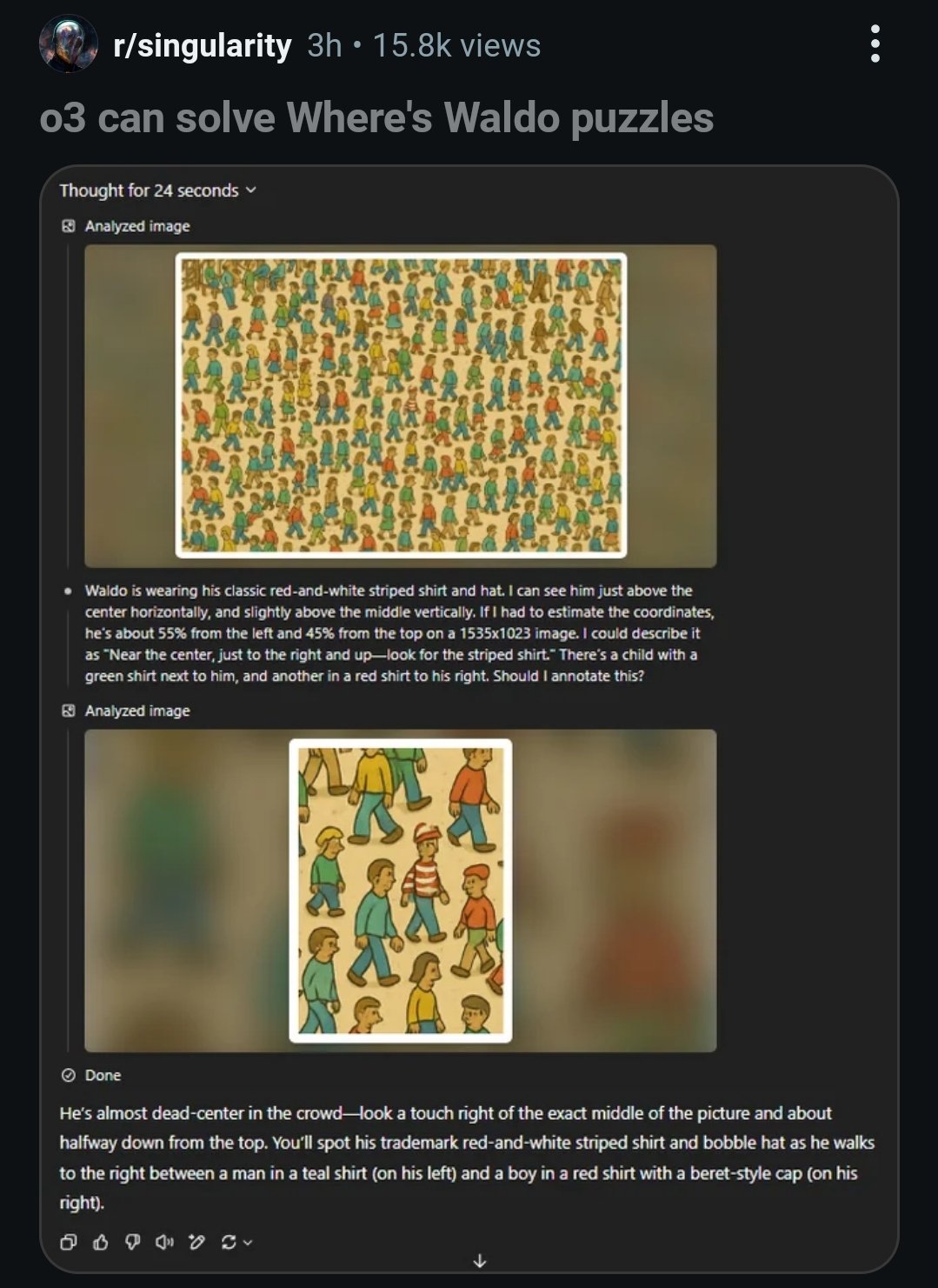
📍 El nuevo superpoder del georazonamiento: “Geoadivinación”
Una de las funciones más sorprendentes de estos nuevos modelos es la llamada “geoadivinación” (geoguessing), un término popularizado por Ethan Mollick. ¿En qué consiste? En que el modelo, a partir de una imagen sin metadatos de ubicación, puede ofrecer coordenadas y un mapa preciso del lugar donde fue tomada.
Apoyado en su capacidad para ampliar imágenes, extraer texto visual, reconocer patrones arquitectónicos o culturales, realizar búsquedas web y razonar paso a paso, ChatGPT ofrece una dirección con argumentos visuales y textuales para justificar su inferencia.
- 📸 Reconoce señales, monumentos, arquitectura o clima.
- 🔍 Compara con imágenes ubicadas en la web mediante búsqueda visual.
- 🧠 Descompone visualmente el proceso inferencial.
👁️ “Un modelo que interpreta el mundo visual como una persona… pero con acceso a todo internet.”
🎓 Aplicaciones prácticas en educación: transformando lo que enseñamos y cómo aprendemos
📈 Nuevas formas de aprendizaje basadas en imágenes e inferencias
Este tipo de capacidades tiene un potencial brutal en educación. Desde enseñanza de geografía, análisis histórico de imágenes, etnografía visual o estudios culturales, hasta desarrollo de habilidades críticas, las posibilidades que abre son transversales.
- 🌍 Geografía e historia: analiza imágenes históricas localizándolas automáticamente.
- 📚 Educación literaria: contextualiza escenas visuales para comprender relatos o novelas gráficas.
- 🔬 Ciencias naturales: deduce datos medioambientales o geológicos con imágenes satelitales.
Ya no hablamos solo de analizar contenido textual. Hablamos de trazar un pensamiento intermodal que conecte lenguaje, imagen, datos de ubicación e inferencia.
📘 “Imagina enseñar historia con imágenes reales que el sistema contextualiza en tiempo real, discute y compara. Estamos hablando de aprendizaje activo, localizado, personalizado y argumentado.”
📚 Herramienta de razonamiento activo para estudiantes
Esta tecnología no solo sirve al docente: puede ser una app pedagógica en sí misma. El estudiante puede preguntarle al sistema: “¿Dónde crees que se tomó esta foto? ¿Por qué?”, y luego analizar críticamente la argumentación del sistema.
Esto promueve justo lo que buscamos en la educación contemporánea: pensamiento crítico, evaluación de fuentes, argumentación lógica, lectura multimodal y alfabetización mediática.
- 💡 Estimula la curiosidad científica con demostraciones visuales.
- 🧠 Desarrolla la metacognición: los alumnos reflexionan sobre cómo el sistema razona.
- 🎯 Fomenta la evaluación reflexiva de la información: ¿está justificada esa hipótesis?
“Sigue leyendo que esto mejora. No es solo lo que ve la IA… ¡es cómo lo entiende!”

⚠️ Retos éticos, sesgos culturales y el riesgo de la ilusión de ‘veracidad’
🛑 ¿Podemos confiar en las inferencias visuales de la IA?
Como toda tecnología poderosa, estas habilidades plantean problemas profundos. El primero: la opacidad epistemológica del razonamiento ‘probabilístico’ del modelo. Aunque el sistema explica paso a paso cómo llega a una determinada localización, lo hace desde asociaciones estadísticas, no desde conocimiento explícitamente certificado.
Esto puede conducir a una peligrosa ilusión de precisión: la IA parece saber, pero en realidad, “infere” desde patrones probabilísticos que pueden ser erróneos, sesgados culturalmente o poco verificables.
🥽 “La IA no ve como nosotros. Se acerca… pero desde otro lugar. Seguimos sin entender qué ojos tiene.”
🔍 Riesgo de sesgos y discriminación algorítmica en entornos educativos
Además, como ocurre con todos los modelos de IA, hay un gran riesgo de reproducción de sesgos culturales o de datos entrenados. Es fácil imaginar escenarios en los que, por ejemplo, la tecnología asocie automáticamente ciertos elementos visuales con determinados países, etnias o clases sociales.
Esto puede distorsionar la experiencia de aprendizaje, reforzar estereotipos e incluso invisibilizar complejidades históricas o culturales si no se usa con criterio pedagógico y reflexión crítica.
- ⚠️ Riesgo de errores sistemáticos enlazados con sesgos en los datasets.
- 🧠 Necesidad de un uso transparente, crítico y supervisado.
- 🧾 Importancia del acompañamiento docente en el análisis de resultados.
“¿Te lo habías planteado así? A veces ver demasiado nos hace pensar mal.”
🚀 Perspectivas futuras: ¿Agentes autónomos expertos en razonamiento visual?
🤖 Del razonamiento visual al agente educativo proactivo
Una de las novedades más sutiles que llega con o3 y o4-mini es el comportamiento agente. Es decir, estos modelos ya no necesitan que se les dé una orden aislada; pueden actuar por iniciativa propia, haciendo múltiples pasos razonados, buscando en internet, interpretando imágenes y entregando resultados con estructura lógica.
¿Qué significa esto en educación? Que podríamos tener agentes expertos autónomos que analicen evidencias visuales de un portafolio estudiantil, propongan sugerencias personalizadas, diagnostiquen dificultades o incluso planteen actividades a medida a partir de imágenes que el propio estudiante incorpora.
- 📐 Evaluaciones adaptativas basadas en análisis visual.
- 🖼️ Análisis de proyectos artísticos, maquetas o composiciones gráficas.
- 🕵️ Retroalimentación automatizada y contextual sobre tareas visuales.
✨ “Vamos camino a tutores inteligentes que no solo lean… sino que ‘miren’ con inteligencia argumentativa.”